







PX9 is a lightweight gfx & map compression library, intended to replace PX8. It uses the same ideas and interface as px8, but is smaller (297 214 tokens to decompress), and requires zero configuration.
To compress some data:
px9_comp(x,y,w,h, dest_addr, vget) returns the number of bytes written x,y,w,h is the source rectangle (e.g. on the spritesheet or map) dest_addr is where to write it in memory vget is a function for reading values (e.g. sget when compressing from spritesheet) |
To decompress it again:
px9_decomp(x,y,src_addr,vget,vset) x,y where to decompress to src_addr is a memory address where compressed data should be read from vget, vset are functions for reading and writing the decompressed data (e.g. pget and pset when decompressing to the screen) |
Unlike px8, the vget function does not need to return 0 when x,y are outside the destination rectangle
Workflow
You can use px9.p8 as a utility for compressing other carts' data by replacing _init() with something like this:
reload(0x0, 0x0, 0x2000, "mycart.p8") clen = px9_comp(0, 0, 128, 128, 0x2000, sget) cstore(0x0, 0x2000, clen, "mycart_c.p8") |
This would compress the spritesheet from mycart.p8 and store it in the spritesheet of mycart_c.p8, using memory from 0x2000.. as a temporary buffer. See the PICO-8 Manual for more information about reload() and cstore().
In the release cartridge, you only need the code from tab 1 (px9_decomp) in order to decompress, which should be just 297 214 tokens.
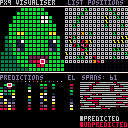
The Algorithm
// expand for an interactive visualiser and technical details.
Version History


This is really impressive. I imagine this would be super useful for people like @nextlevelbanana in making slideshow presentations based in PICO-8! :D


Nice! That token saving is not to be sniffed at. Although px8 seems to do a better job at compressing the image in this cart - 1274 (px9) vs 1092 (px8) bytes?
It fared better against other image data I tried though (for some 128x128 sort-of perlin noise it did about 2.5kb vs px8's 2.9kb).
I replaced the logic for getval() in the decompressor and saved 4 tokens. I think it also might be slightly faster, especially when fetching larger bit strings, but not much.
(I also unified the tabs, just because it was driving me nuts.)

Nice one @Felice -- I included this version in px9-3.
@Skulhhead1924 The first two version (0, 1) were tests that I didn't post yet. Not sure what you meant, but you can always load the most recent version one from PICO-8 commandline with:
> LOAD #PX9
@Catatafish That's.. actually quite a surprising difference! I haven't done a thorough comparison, but in general their performance is similar, on average. It might be possible to sometimes squeeze a bit more out of px9 by using thing's like px8's remap() function (which reads pixels 8x8 sprite by sprite), but I imagine the smaller token count is more valuable.
I squeezed a few more tokens out of the decompressor, down to 277 in total. I had to minify it a bit so it'd actually fit in a project I'm using this in, sorry.
Also, if you swap the serialization order of h and el b in the compression routine you can factor out h & save 2 more tokens in the decompressor.
edit: got my variables mixed up
@Catatafish Can you explain why a couple of your replaced gn1 calls start with tot==0 or 2 instead of 1?
The gn1"2" version is an optimization for gn1()+1 that rolls the +1 into the call. The h=gn1"0" version is the same thing, done to avoid a later use of h-1.

I would love to check out the code, but PICO-8 "CANNOT CONNECT TO BBS" for some reason. is the code snippet you posted in the description all I need to compress and decompress? and am I too late to make PICO-Art? (Hee Hee! PICO-8 PICO-Art!) Thanks!
Hi -- the site was down for a few moments while doing some maintenance. Please try again now!
yes, those snippets plus the contents of the cart are all you need (tab 1 for decompression and tab 2 for compression)
That was fast. I accidentally closed this tab and when I reopened the tab I saw your comment. Anyway, I tried to run a game I have never played, unable to connect to bbs. I try to download a game, download failed. I also tried reinstalling both pico-8s (yes, I have two PICO-8s on the sidebar (mainly cuz I have two screens)) but, nope. thanks for speed-replying!
wow, 3 comments in a row that's a first. oh after I post this it will be four.
Ooh! just noticed the new CIRCLE TOOL! gonna be a big help in art.

Hey @zep, I think I've encountered a bug where the returned length of compressed data is reported 1 byte too short, and I was chopping off this extra byte which lead to some corruption when decompressing.
Just incrementing clen immediately after compressing works around this issue (but sometimes uses 1 extra unnecessary byte I think).
I may be able to come up with an example if that's helpful.
I have a version of this that's been updated for 0.2.0 functionality/performance and has the optimizations @Catatafish made above.
Now that @mrh has pointed out the bit-flushing bug at the end of the file, I've also fixed that in my version.
I don't mean to step on @zep's toes, but I think I should just offer up this version, since it's a rollup of everything that could have been done to PX9 since zep's last official version.
Notes:
- Functionality
isshould be identical - Fixed the bit-flushing bug at EOF
- Perf should be better in 0.2.0
- Down to 273 tokens
- Some code rework because I'm OCD (sorry zep)
Here's the cart:


First off, thanks for the awesome tool!
Gratuitous feature request:
Is there an easy way to extend this to compress to and decompress from strings? (e.g. the decompress function could use a vget function to access the string, but the compress function just stores to cart memory.)
With the vget vset functions, can this be extended to compress to or decompress from strings?
1) compress from spritesheet to file on disk using (printh str [filename] [overwrite])
2) decompress from string in code section to spritesheet.
--end gratuitous feature request that I am just being too lazy to code myself
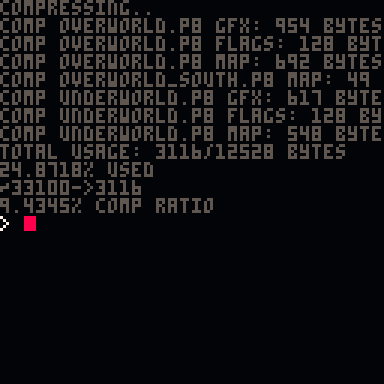
Thanks for testing, @mrh, glad to hear I didn't break it. :)
By the way, I typo'ed the token count above. I said it was down to 274 but it's actually 273. Hey, every token counts, right? :)
@electricgryphon, @zep, et al
I wrote a version of the decomp that can read from a base128 string or from memory, depending on whether its passed a string or a numeric address as the src. It's 320 tokens vs. 273 for just memory, which is a fair bit more, so here's a cart with all three versions of the decompressor, with a compressor that can write to memory or strings.
See the first tab for updated usage details in the big comment block, but here's the TL;DR:
- 320 tokens for px9_decomp(), which can now take an address or a string.
- 273 tokens for px9_mdecomp(), which was the existing memory-only decompressor.
- 283 tokens for px9_sdecomp(), which is a string-only decompressor.
- Compressor can now take nil as a dest addr, causing it to return a string instead of compressed len. Use #str to get compressed len.
Gryph, regarding writing to disk, you'd obviously just printh() the resulting string yourself.
Edit 1: Hotfix for a bug @electricgryphon reported below.
Edit 2: After investigation, we've found that some images encoded as raw hex strings will produce smaller carts after .p8.png compression than using PX9-compressed strings. The sample image in zep's cart is smaller via PX9 string, while @electricgryphon's test image below is smaller via raw hex string. The hot take here seems to be that an image with a lot of patterns will make a smaller cart with raw hex, while an image with a lot of solid areas will make a smaller cart with PX9. So people might need to pick and choose when it comes to string encoding. Memory encoding will always benefit from PX9 though.

Found a typo in px9_decomp, line 272
cache|=(((ord(sub(str,i,i))) or 0)&127)>>>16-cache_bits should read cache|=(((ord(sub(src,i,i))) or 0)&127)>>>16-cache_bits |
With that change, this works awesome!
Out of curiosity, the output string is mostly symbols and kanji. Is there a reason to use this for encoding data as opposed to ASCII? (eg:"◝◝◝♥◝◝◝♥ョ⧗🅾️◝★スすクュ..." vs "sdf53RG4rads#$T%$..." )
Well, for my particular target image (ordered 8x8 dither with no solid areas) this doesn't look like a good compression fit when I look at compressed code size after storing as a string in the code section.
(It does take up less space in the gfx section of the file though, just not in the code section, if that makes sense.)
Total Delta (compressed code) Initial compressed code size = 9122 0 String compressed code = 15045 5923 Hex compressed code = 15286 6164 Raw (uncompressed hex) = 12901 3779 |
So for this particular image/use case, I'd be better off pasting the image as a raw hex string.
Here's the image:

Wait, how the heck is it even working with the wrong variable name there?
...
OH!
Okay, I see, the test code actually, by complete coincidence, used a global called "str" to hold the compressed data, which is what "src" points to inside decomp. So it works, but fails if I change the global to "image". What a devious little bug! It was in sdecomp as well, sigh.
Thanks for catching that! I've fixed, tested, and updated my version of the cart. :)
I used chars 128-255 instead of alphanumerics because it meant I could use the whole continuous range, storing the value raw with its top bit set, so I could just clear the top bit during decode, no worrying about which chars are legal in strings (e.g. single/double quote, backslash) and closing gaps or table lookups and stuff like that. It looks funky but with the current cart format there's no compressed-size hazard in using the upper range anymore.
Also, I guess I'm not surprised that your image fares better as a raw hex string. The .p8.png compressor is much better than it used to be while PX9 seems to do well mainly with large continuous blocks of color. It might only matter if the hex-string version of your raw data is too big for the source code window or something.
Maybe try your method with other bases than 16? Like base64 or my version of base128, for instance. Encode/decode is pretty simple. I'm curious whether or not changing the bit stride like that will mask patterns out and make the .p8.png cart compression worse.
Actually, I tried the test I suggested above. Base64 and base128 both cause the compressed size to increase, so yes, they do obscure the patterns the .p8.png compressor is able to make good use of.
So yeah, I agree: if you can afford the space in your 64k source code window, a simple hex encoding that gets compressed by the built-in source code compressor is probably the best bet for your kind of image.
I'm not sure if this will be true for all image types, though. Yours has a lot of regular noise to simulate RGB, but most games use more cartoony visuals, like zep's sample image, whose px9 string performs markedly better after p8.png compression than a raw hex string version does. If you or anyone else has some real-world game image samples for me to try, let me know and I'll run them through this little base16/64/128 test bench I wrote to see, because if the string encoding isn't worth it, I should just remove that and de-complicate the library.
(Side note: interestingly, if I encode almost 32k worth of graphic data similar to yours into an almost-64k source hex string, it compresses to just about the compressed p8.png size limit. Nice work, @zep!)

Thanks for this utility!
I've been playing around with it as a way to compress smaller images (e.g. portraits for an RPG), and may have found a bug-- it seems if you use px9_decomp to a location on the screen with x0>0, you get a distorted image, caused by decomp incrementing y whenever screen x position>width (fine if x0=0, but if x0>0 this happens mid-image). Example:

I implemented a fix to the main px9_decomp as px9_decomp2 in that cart that adds 6 tokens, but there may be a more token-efficient way, and I didn't update all of the functions-- I wanted to share quickly and see if this makes sense or if I'm missing something.
Thanks @icegoat
The following code kicking around at the end of px9_decomp looks like it was from an early WIP, is completely meaningless, and otherwise redundant. Ridiculous! So I removed it for v5, and as a bonus we're now down to 262 tokens \o/
-- advance x+=1 y+=x\w x%=w |

Nice work!
I think I saved 4 tokens on the vlist_val methods, thus bringing them px9_decomp and px9_comp down to 258 and 430 tokens respectively:
local function vlist_val(l, val)
-- find position
local v=l[1]
for i=1,#l do
l[i],v=v,l[i]
if v==val then
l[1]=val
return i
end
end
end |
(Edit: there was a caveat, see the next post for details and a balanced mitigation.)
WHO WANTS TO SAVE 11 MORE TOKENS?
I THINK YOU DO!

Details:
Took advantage of recent API improvements to smallen vlist_val() even more, using add(l,deli(l,i),1) rather than shifting the MRU entry using direct list manipulation loops. Also removed unused return value. Now 247 tokens.
Ah. Well. Darnit.
Houston, we have a problem.
I figured I ought to make sure I wasn't slowing down the algorithm by calling out to functions, so I added timing code to the demo (included in the cart below for future use & comparisons), and my concerns were justified.
Turns out add() and deli() don't have enough of an internal-loop advantage over interpreted manual manipulation to keep up, performance-wise. They dropped decompression speed by half, which is a hefty price for a handful of tokens.
The cart below has yet another implementation of vlist_val(), back to using manual manipulation again, but a better par in code golf. Sadly this saves only 4 tokens over Mathieu's previous record (258→254 tokens), not 11, but on the upside, it outperforms all previous implementations that I've checked.
I guess it's up to the community to choose: size vs. speed
I included both versions of the function, with the smaller-but-much-slower one commented out by default:

Thanks @Felice! I went with 7b for the head cart, as it's more likely someone will come back to this thread looking for tokens than for speed.

Can there be a visual diagram of how this algorithm works? I'm struggling to understand your text description of the algorithm. The code looks too complex for me to understand as well.


Unsure if anyone would find this useful, I am using decompression at 0x4300 in screen format so I can then memcopy to screen... the funcs I inject to PX9_DECOMP are the following:
pxget=function(x,y)
local addr=0x4300+x\2+y*32
local v=(x%2==0 and band(@addr,0x0f) or shr(band(@addr,0xf0),4))
return v
end
pxset=function(x,y,v)
local addr=0x4300+x\2+y*32
local lv=band(@addr,x%2==0 and 0xf0 or 0x0f)
lv=lv+shl(v,x%2==0 and 0 or 4)
poke(addr,lv)
end
-- copy to screen buffer per line
screendump=function(w,h)
for y=0,h-1 do
memcpy(0x6000+y*64,0x4300+y*w\2,w\2)
end
end
|
The screendump function probably can be reasonably easy to update to support x,y positioning if not dumping the full screen though odd x positions could be tricky to handle (maybe initial pset+memcopy+trailing pset?). I needed to move elements on top a full-screen image and decompressing every frame is not fast enough.
Oh! importnat... 0x4300 has only up to 0x5600 available space so a full screen cannot be placed there... I was using this for MODE3 (64x64) screens!
Hope this helps you!

@zep I saved 13 tokens in the vlist initialization code by changing this:
-- create vlist if needed
local l=pr[a]
if not l then
l={}
for e in all(el) do
add(l,e)
end
pr[a]=l
end |
to this:
-- create vlist if needed
local l=pr[a] or {unpack(el)}
pr[a]=l |
This saves 13 tokens, but increases runtime on the example image by 2% (0.1491s -> 0.1528s)
If you add 5 tokens back and do this instead, the time goes down a tiny bit: (0.1491s -> 0.1489s)
-- create vlist if needed
local l=pr[a]
if not l then
l={unpack(el)}
pr[a]=l
end |
(I haven't done more rigorous testing than this, and the 2% slowdown seems acceptable to me, but hopefully this info is helpful if someone cares to look into it more.)
Here's the updated cart (it also includes a changelog entry + a few whitespace changes + a typo fix: "px8"->"px9")

Alrighty, I've saved another 7 tokens by completely redoing the order of the bitstream. px9_decomp now runs about 2% slower on the example image (likely because I'm reading data one byte at a time instead of 2 bytes at a time) (.1528s -> .1557s)
I'm not sure how far is too far, in terms of token/performance tradeoff. But anyway, here's the cart (234 tokens to decompress)

Thanks @pancelor, amazing improvements!
(I just realised now the head cart was not up to date, and copied kuhobepase-0 to px9-9)
Interesting to see @carlc27843 was able to get 10% better compression by replacing the span length/index encoding with arithmetic encoding used in Nebulus:
https://carlc27843.itch.io/nebulus
Using arithmetic encoding would of course cost more tokens in general, but was cheaper in that case because he already needed it for other parts of the program.

Here's a demo of arithmetic coding in a px9-like decompressor.
- compressed size is 1119 bytes (px9 was 1275; so this is 156 bytes or 12% smaller)
- total tokens is 348 (px9 was 234), however my game uses vlval, unpr and fpaq1d functions in other places, so the image-specific function tokens is 113
- decompress time is 0.5754 seconds (px9 is 0.1491 seconds; so this is nearly 4x slower!)
It's tradeoffs all the way down... I'd guess few games need the extra space so the official px9 is most likely the best choice for most use cases.
(This particular implementation has other restrictions, like width/height must be <=256, and compressed data must be stored in ram).


Been using my own string-based compression systems for a while, but to store enough sprite data to make large games feasible, I need a codec that can compress to memory as well, and PX9 is the best solution I've found for that.
With that in mind, here's my contribution. It's a new variant included alongside Pancelor's 234 token version, and for 254 tokens it can decompress data from either memory or full 8-bit strings. Performance is pretty close, ~0.39% slower when decompressing from memory, and ~1% slower when decompressing from strings. The strings are automatically output to the clipboard when compressing, just be sure to press ctrl+p before pasting them.


Can I have some help with this? I want to make a library of images for something and need a way to store them and this seems like the best option, can someone explain how to do it?


I think I found an edge-case where the compression routine fails. I fell across it while working on silly splash screens. After some playing around, the failure mode can be "corrected" by judicious application of certain background colors (EDIT: See update in this same post). I've added a (slightly) modified test-cart to replicate the issue. If nothing else posting this for others to see if they encounter the same issue. Here is the de/compressed result:

UPDATE: Further experimentation suggests that if the source image doesn't have enough entropy, the compression algo becomes confused. If you add some colored circles to this test cart, then the algo snaps back into perfect performance. The example image below will de/compress perfectly.

UPDATE 2: I thought the text was perhaps causing the issue originally, with the subtle interpolated colors around the letter outline, but plain color fields will elicit the same behavior. This is in-line with the "not enough entropy" line of thought, but deleting the text to generate the same results provides a much easier test-case.

good catch @djclemmer! I introduced this bug (oops) in #px9-9 when I made the decompressor read single bytes instead of bytes pairs (@src instead of %src). This causes problems when there are >255 predictable pixels in a row, just like you said: "if the source image doesn't have enough entropy"
I fixed it, and also saved another 19 (!) tokens in the decompressor, along with a slight speed-up. There were a few unused variables sitting around that I removed, but the savings mainly came from changing getval() from this:
local cache,cache_bits=0,0
function getval(bits)
if cache_bits<8 then
cache_bits+=8
cache+=@src>>cache_bits
src+=1
end
cache<<=bits
local val=cache&0xffff
cache^^=val cache_bits-=bits
return val
end |
to this 3-line version:
-- read an m-bit num from src local function getval(m) -- $src: 4 bytes at flr(src) -- >>src%1*8: sub-byte pos -- <<32-m: zero high bits -- >>>16-m: shift to int local res=$src >> src%1*8 << 32-m >>> 16-m src+=m>>3 --m/8 return res end |
(I also reversed the order the bits are pushed during compression)
I didn't include @JadeLombax's string code; you should be able to replace $src with (ord(datastring,src)>>16|ord(datastring,src+1)>>8) but it seems a bit token-heavy... plus I think you need src+2 as well to avoid the >255 bug (in this case it might be a >511 bug)
215 tokens: (for the decompressor)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
edit: oh actually, something like this should work to decode from strings:
local function getval(m) poke(0x8000,ord(thestring,src,4)) local res=$0x8000 >> src%1*8 << 32-m >>> 16-m src+=m>>3 --m/8 return res end |
Nice optimization there! I'll see if I can get a version working with strings, but if not I guess I'll just stick with the higher-token version. I'm adapting PX9 for storing multiple spritesheets in a single cart along with a large compressed world map, so I need to have the string capability, and the images I'm storing should have plenty of entropy to avoid the bug djclemmer pointed out.
@JadeLombax, I am using the older v10 string compression routine (not the new v10 which fixes the low-entropy bug but I think removes string support). My typical workflow is to setup a utility cart with PX9 code loaded in, draw up my assets and then run px9_comp on the assets, writing the string out to a file using printh. As a debug test one time, I immediately ran px9_decomp on a string I had just px9_comp'd, and it resulted in garbage. But the string written to the file, when copy/pasted into my other working cart, worked fine. I have been through this to make sure I'm not making some stupid mistake - Is it your understanding that I should be able to immediately do a px9_decomp(pget, pset) using the string generated from px9_comp(sget) ?
[Please log in to post a comment]