








I was reading up on Bit Arrays to learn more secret bitwise knowledge, and stumbled onto a very clever way to count bits, via Hamming weights and a magic multiplication number. Short story is that this led to efficient fullscreen Anti-Aliasing for 1-bit screen data (colors 0 and 1 only).
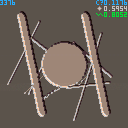
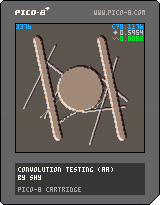
Other convolution shaders are easily doable with similar techniques. This one takes every pixel and adds weighted amounts of the neighbors in this way:
1 131 1 |
You might be able to do gaussian blurs with a larger sampling neighborhood, or things like Conway's Game of Life. I'm really surprised how efficient some of these techniques are, even on pico-8. Counting every single 1 in the entire screen data is only ~6% CPU @ 30fps.
UPDATE
I cleaned up the interface, added color palettes, and optimized a bit, so this should be finished now. Managed to get a super-optimized version of the AA working via loop unrolling, but also added @Felice 's adjustment to the version with fewer tokens. There's a secret demo-like effect to play around with now too, discovered via offset bugs. Calling this experiment done!

.

UPDATE 2
Wanted to test the limits of optimization, at the cost of tokens. Original AA function is 101 tokens, faster version is 434, fastest version is 1397, but officially runs twice as fast! (9% CPU at 30fps) I don't think I can push this idea any further, and there are diminishing returns, so the middle speed is probably the best choice in most cases.
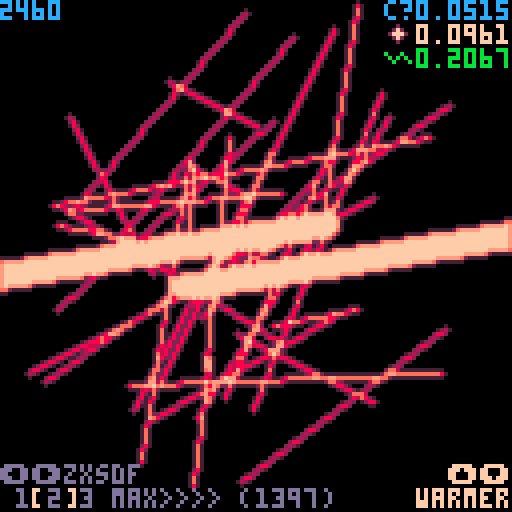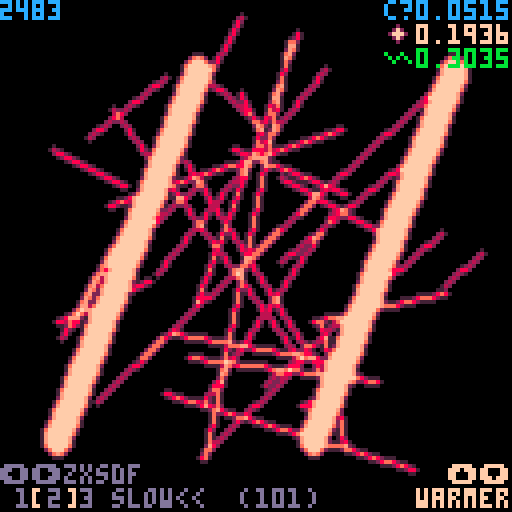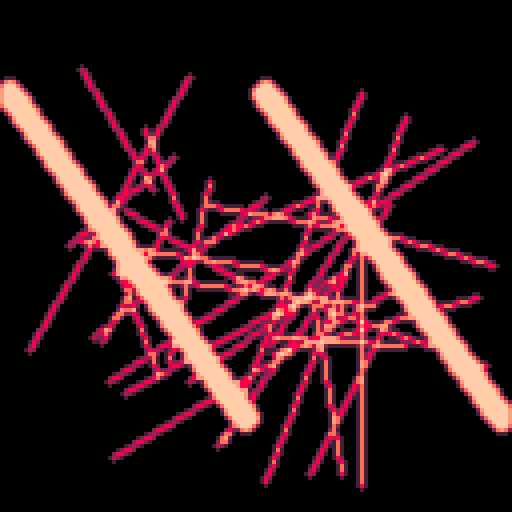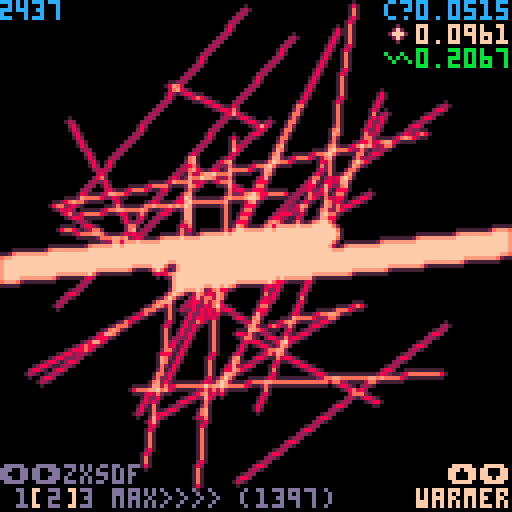
UPDATE 3
Very slight changes based on @freds72's optimization suggestion. Times and token counts are down across the board!
UPDATE 4
3%CPU@60fps improvement to the middle function for +30 tokens (or a 1% improvement for -24 tokens, commented out in the code). The max speed function becomes less relevant!

This is super cool! It took me a sec to get it - the two things I had to realize were that (a) it's safe to treat addition here as being vectorized over pixels because you know nothing will overflow, and (b) multiplication is a bunch of shifts and adds, so the choice of constant is just picking which of those shifts you want to keep.

Nice!
Heads up, you can get a small (just one cycle really) savings in your inner loop by offsetting i so that at least one use of it doesn't require an addition or subtraction.
Change this:
for i=j,j+56,4 do
n=$(i+4)
poke4(i-0x3000,
$(i-64)+$(i+64)+c*0x13.1+
(n<<28)+(b>>>28))
b=c c=n
end |
To this:
for i=j+4,j+60,4 do
n=$i
poke4(i-0x3004,
$(i-68)+$(i+60)+c*0x13.1+
(n<<28)+(b>>>28))
b=c c=n
end |
Takes the AA pass from 0.4035 down to 0.3896 @ 60fps.
Emboss, because why not:
{kind=link}
{kind=link}
@Felice: Thank you! I patched in your quick optimization, and also took a stab at a loop-unrolled version, which cut the AA pass down to 25% @ 60fps. Could probably optimize further by peeking into the b/c/n's cyclically, so you don't have to reassign each loop, but that's likely not worth triple the tokens.
@luchak: This is fantastic! I never even considered this, and I'm sure there are other great visual effects that could use some of your ideas here as a basis. Really nicely done!
Glad you liked it! You did the hard part, I just changed some constants around. It might be fun to experiment with changing the kernel at runtime to get something like a dynamic lighting effect....
[Please log in to post a comment]