





I am thoroughly confused at this:
cls()
print(stat(0))
a=""
for i=0,8191 do
a=a.."*"
end
print(stat(0))
a={}
print(stat(0))
for i=0,8191 do
a[i]=255
end
print(stat(0))
|
If I'm reading this correctly, a numeric array of the same length as a string takes far less space ?
In fact what's really weird is if you run it a few times, the last STAT says 2048, matching the others instead of the 62.8115 - but the string maintains at 2048.
Which takes more space ... and why ?

Here is the example using debugger:

{kind=link}
-- test of stat ---------------
-------------------------------
-- main program ---------------
function main()
dbc={13,6,11,12}
cls()
print""
scrn=""
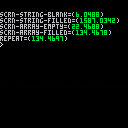
db("scrn-string-blank",stat(0))
for i=0,127 do
for j=0,127 do
scrn=scrn.."*"
end
end
db("scrn-string-filled",stat(0))
scrn={}
db("scrn-array-empty",stat(0))
for i=0,127 do
for j=0,127 do
scrn[j+i*128]=255
end
end
db("scrn-array-filled",stat(0))
db("repeat",stat(0))
end--main()
-- functions ------------------
-- simple color text
function cprint(t)
local c,s,p,x,y=0,0,7,peek(24358),peek(24359)
for i=1,#t do
if s==0 then
c=sub(t,i,i)
if c==":" then
p=dbc[tonum(sub(t,i+1,i+1))]
s=1
else
print(c,x,y,p)
x+=4
end
else
s-=1
end
end
print("",0,y)
print""
end--cprint()
-- david's delightful debugger
-- don't leave home without it!
function db(a,b,c)
local n,y,p,t,w=0,0,0,"",""
if (not(first)) first=1 print""
if (b==nil) b=a a=nil
if (a!=nil) t=":2"..a.."="
w=typ(b)
if (w=="x" and a!=nil) t=t..":1nil"
if (w=="s") t=t..'":4'..b..':2"'
if (w=="n") t=t.."(:3"..b..":2)"
if (b=="") t=""
cprint(t)
if not(c) then
y=peek(24359)
for i=0,2 do
repeat
p=8-p
if (n==1) p=0
rectfill(0,y,3,y+4,p)
for j=0,7 do
if (btn(🅾️)==true) n=1
if (n==0) flip()
end
until (i!=1 and btn(🅾️)==false) or (i*n==1)
end
end
end--db(...)
-- same but no wait for key
function dbs(a,b)
db(a,b,0)
end--db(..)
-- return type of var as 1-char
function typ(a)
if (a==nil) return "x"
return sub(type(a),1,1)
end--typ(.)
main()
|

Lua is a garbage-collected language.
When you do your 8192 string concatenations, you're actually producing 8192 separate strings on the GC heap, because Lua strings are immutable (read-only, basically) and appending one to another produces a third, rather than extending the first. These intermediate strings end up orphaned and will eventually be garbage-collected, but until then, yes, the GC heap will seem to be using much more memory.
Try again with 1024 concatenations of "12345678" and you should find that the usage goes down to 1/8th of what it was.
(this may vary if the garbage collector fires off during concatenation, mind you.)
Now, that's a name I've not heard in a long time. ... Obi-Wan - ... Sorry, wrong story. :)
No, Garbage Collection. Yes it has been a VERY long time since i heard that name. You could get that in Applesoft BASIC but not Integer Basic oddly enough for the Apple. And it was HORRENDOUSLY slow when it ran.
Okay, well, here's the clicker then, Felice. Can I FORCE a Garbage Collection in PICO with a command or poke or something so I know where my actual memory stands when I test it ?
If ZEP is gonna limit the size of our cardboard boxes, I will most certainly want to know its dimensions by measurements, weight, volume, and density - to see what I can get away with ...
... or is there some other way of accurately measuring just how much memory variables and arrays in RAM are taking ?
I'm not aware of any way to force a garbage collection. It probably just happens when memory gets too fragmented or tight.
Luckily the Lua GC is pretty inexpensive, given that the GC heap in PICO-8 can only hold up to 2MB of data and it's run at native speed, rather than PICO-8 speed. It's basically hidden from you inside your virtual PICO-8 machine, so it's not a performance issue you need to concern yourself with. I've written code that really abuses it and I don't recall ever seeing it slow down.
I re-ran my code stopping it after the string and stopping it after the array fill, Felice.
Apparently once you enter command mode (DOS if you will) a garbage collection automatically takes place right then.
And, I got an entirely different set of numbers typing out PRINT(STAT(0)) directly there. Oh yes, the string was a lot smaller than the array.
I figured it would be since a single variable automatically sucks up 4-bytes of usage (all that real number and stuff) and a string, well, if done properly, only takes the number of bytes of its size, plus a likely 2-other bytes to show its length.
Which leaves me ... darnit ... looks like strings are the way to go for deep and detailed arrays, and not quite so easy to manipulate.
I remember working in the Sinclair and it had a unique way of reading string character data.
A$="Apple" print A$[1] print A[1] |
"A" would be the result for the first one and "65" would be the result for the second one.
I've never hit the edge of memory in PICO yet. Not sure what it would take to fill it up - hopefully, I'll never find out. :) Thanks for helping me resolve this question, Felice !
While I am indeed looking at the video tutorial in PICO on how to properly use those 3-system functions, from what I've seen you always were quite good at recursive programming. I.E.: that maze program you wrote.
I doubt I'll find a class or an understanding to that.
Recursion is a tricky thing to get your head around at first, but you get used to it after a while.
I will say that I wish you could do ASC$/CHR$ style things natively, but you can definitely write your own, at least. It just wastes some tokens to do it. I have the impression like zep didn't want us to consider the character-integer relationships to be set in stone, but they kind of are anyway at this point, so it would be nice to have those built in.
If you want a quickie solution for those, you can use a table-lookup method:
_ascchr="\0\1\2\3\4\5\6\7\8\9\10\11\12\13\14\15\16\17\18\19\20\21\22\23\24\25\26\27\28\29\30\31\32\33\34\35\36\37\38\39\40\41\42\43\44\45\46\47\48\49\50\51\52\53\54\55\56\57\58\59\60\61\62\63\64\65\66\67\68\69\70\71\72\73\74\75\76\77\78\79\80\81\82\83\84\85\86\87\88\89\90\91\92\93\94\95\96\97\98\99\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
asc,chr={},{}
for a=0,255 do
local c=sub(_ascchr,a+1,a+1)
asc[c],chr[a]=a,c
end
>print(chr[33])
!
>print(asc["!"])
33
|
[Please log in to post a comment]