







...but it never actually starts :)
I wanted to do a proper Bad Apple!! rendition for Pico-8, but wound up hitting the compressed size limitation way too early. So I've decided to do a little trolling, and only include a looped intro. I'm still kinda proud of it though, because I managed to do it in full 128x128 resolution at 15 FPS.
I've tried my best with the drums in the intro, but couldn't figure out how to emulate hi-hats properly. Also, it doesn't match the original BPM of 138 - it's set at speed 13, which is slightly slower, but speed 12 is slightly faster.
For the video frames, I implemented a quadtree-based compression method and encoded the results in base32. I'm sure there are still ways to improve compression - for example, each frame is now compressed independently, so there's still redundancy.
If you have any other ideas, please tell me in the comments!


Haha, awesome troll. While I see the appeal of 128x128, using the 64x64 poke seems a no-brainer given the constraints.
What you can do is using multiple carts : when you run a cart from another one, everything LUA related is lost, but a lot of the 64K pico-8 memory is not cleared (including the 2nd 32K), so chain carts to fill every bit of the uncleared memory with compressed data, and do the decoding/playing in the last of the chain.
Alternatively, you can drop BBS support and add a lot of data carts to the project.
@RealShadowCaster thanks for your feedback!
> using the 64x64 poke seems a no-brainer given the constraints
Due to how quadtree compression works, I'm actually almost never poking individual pixels - I instead fill bigger squares whenever possible. Because of that, I am able to even hit 30 FPS - I only settled on 15 FPS because of size considerations.
I can lower the resolution just to help the compression, but it won't help that much here, since the whole video is still way too large.
> What you can do is using multiple carts
I am considering it, except loading each cart introduces sizable and not-quite-predictable delay, and I wanted to, ideally, sync this to music. I could, of course, just do some video editing magic for that - but what's the fun in that? :)
My suggestions put all the delay at the start, no more data loading once the music starts to run.
Between the uncleared memory filled by previous carts and the data from the last one that plays the video, I think you could have around 90K of compressed data for a BBS/splore version, and 500K for standalone export.
As a reference, the c64 version was 12fps and 140K of compressed data, so there's hope I think.
@RealShadowCaster I didn't actually know that data can be passed that way, thank you!
I've played around with this, and now I can fit all of Bad Apple on 2 data carts... except it's 64x64 and 1 FPS :) But I'll try to thing of something else to improve.
I've watched the Commodore 64 demo you've mentioned. It seems to use a very different compression approach than me, so maybe I'll try to implement something similar.

I haven't looked at your cart to see what it's doing, but have you seen the 1bit compression demonstrated here https://www.lexaloffle.com/bbs/?pid=113904 ? might help unless you're already doing something similar or better
@kozm0naut as far as I understood, the author of that post doesn't really do any actual compression, they just store 1 bit per pixel. If I'd just done that, a single 128x128 frame would take up 2048 bytes, or 3276 characters in base32.
I do actual image compression on top of that, so whole 128x128 frames become less than 250 bytes, or 400 base32 characters.
But that still only allows me to do about 0.6 FPS if I try to fit the whole video, even when using the upper 32K trick.
Here's something probably worth trying :
same quadtree encoding logic, except the bits of the uncompressed 128x128 (or 64x64 ?) array mean same/different from previous frame, instead of black and white.
By doing so you lose the ability to jump around in the video, but should gain some file size in exchange.
Once that is implemented, you could try having a small KXYT frame header, where K is a single bit telling if the frame is key (IE encoded as black and white instead of as a difference to another frame), X is a signed horizontal offset, Y a signed vertical offset, and T an unsigned time offset. XYT are only there if the frame is not key.
Key frames are rarely optimal, but have the added advantage that you can jump to them, and the 1bit/frame loss is usually an acceptable tradeoff.
Finding the smallest KXYT encoding for each frame might take some time but that's work outside pico-8 so no big deal, and should result in even smaller average frame encoding size, as you'd start to leverage cyclic movements and camera movements.
I might be wrong, but I don't think that implementing zoom based offsets is worth it in this case : too much CPU cost, too little file size gain, and shouldn't play nice with the boundaries of the quadtree cells.
@RealShadowCaster I've finally implemented your multi-cartridge suggestion in a BBS-compatible way! I can now do the whole video at 1.5 FPS and 64x64 resolution:


Did a little test cart that initializes all the 64K memory to the magic value 0xBAADF00D (both appropriate as a non initialized value, and as a bad apple research cart)
At the time of testing, the following ranges are not reset :
0x4300 to 0x5EFF , that's 7KB
That includes the cartdata address range, so beware not to call cartdata before you retrieve data you may have stored there.
0x5F00 to 0x5FFF was voluntarily excluded from the search, as writing in there messes with pretty much everything, and the hardware state keeps changing on its own anyway.
0x6000 to 0x7FFF. This is the 8K of video memory. Perfectly fine to use as data transfer space, love it.
And of course, the high memory
0x8000 to 0xFFFF, 32K
In total that's 47KB of data transferable by memory.
More data can come from the source code of the last cart of the chain, or from the 0-0x42FF range that could be made to contain compressed data, but it seems my 90K guesstimate was optimistic.
@RealShadowCaster wow, thank you! This is insanely helpful!
Right now, I'm using the whole upper 32K, and then fill the 0x0000-0x3000 range from code in the last cart, so 44K of data in total. That allows for about 2.14 FPS (30 divided by 14) at 64x64 resolution.
The idea of using video memory to pass data is definitely a promising one. However, I'll need to rewrite my code somewhat to allow for that - that data needs to be moved out of video memory before the rendering starts, and I don't do that right now, instead peek()'ing it directly from memory addresses while rendering.
I also tested how much data can be passed as a "parameter string", the one that's accessible via STAT(6). Apparently, it's capped at 1024 bytes, so not much luck there.
I've rewatched your 1.5 FPS and 64x64 and noticed something : the 16 top rows and the 16 bottom rows of the video are always black.
Most of the time these will be encoded as 16 quads (8 16px x 16px top and 8 bottom).
I you internally store your frames rolled up or down by 16 pixels, the black bars would be encoded as 4 32px x 32px instead.
Another thing : the quad data strings are significantly compressible. In fact, pico-8 does compress them quite well into the data pngs. While this means you are potentially using less carts, this is not the optimization we want.
Uncompressing the data string into a is something parsable in a timely manner is just extra wait time before the video starts, so compressing the quad data stream with px9 should be worth it.
This would wreck the encoding compression by pico-8, leading to more data carts to fill the memory with compressed data, but the 47KB of data would be worth more picture info in the end.
Question about CPU while decompressing : how much spare do you have at worst? I'm asking because the blocky 64x64 look could be smoothed into a 128x128 with cellular automata logic, if you have the CPU time.
EDIT : the compression bit was bit unclear. I'm not suggestion to use px9 compressing on the data strings :
quad data binary stream -> compressed stream (px9/huffman/whatever works best)-> data strings, base 32 is fine.
> internally store your frames rolled up or down by 16 pixels
Funnily enough, I just implemented that yesterday! I just don't post every single improvement on the BBS, but it's in my Git repo if you're interested: https://github.com/iliazeus/pico8-badapple
> Another thing : the quad data strings are significantly compressible.
I'm not sure about that, actually. I've tested gzip on raw quadtree data, and it compressed 15K of it to about 14K, with less than 1K of a difference. So I don't really know if implementing a complex compression algorithm will be worth it.
I do use a somewhat clever encoding scheme for the data, though. Using the fact that leaf nodes are about 3 times as likely as internal nodes, I use 2 bits per internal nodes, and about 1.5 bits (on average) per leaf node (or exactly 1 bit if it's at max depth, where no internal nodes are possible).
All the optimizations above were included in my 64x64 2.14FPS figure.
> Question about CPU while decompressing : how much spare do you have at worst?
Quite a lot, actually! Since Pico-8 only limits the amount of Lua VM instructions per second, not actual real CPU ones, doing one PSET() takes about the same virtual CPU time as one LINE() or even one RECTFILL() - and my rendering is based around doing RECTFILLs!
So yeah, I'll try to look into some kind of a smoothing algorithm.
I can see why gzip doesn't perform well on a small bit stream when it's elemental input data block is the byte. Maybe give it a raw 1 character per quad input to see if it does better ?
About Rectfill, I've stayed away from it out of habit from other platforms. Knowing that a full screen rectfill with fillp patterns costs the same as a pset feels both wrong and very exploitable. (reminds me the time when I replaced integers with floats ins C64 basic to improve(!) performance) Maybe the new memset is rectfill ! I'll definitly play with it a bit. Any other tricks in the same veign ? I've only really tested map() for performance, and the CPU cost is roughly proportional to the surface of the screen affected, so now I'm curious. Is spr() cost related to screen surface affected like map or fixed cost like rectfill for example ?
@RealShadowCaster to be honest, what I wrote earlier about RECTFILL being fast was mostly based on my (limited) understanding of how Pico-8 works, as well as on what I've observed with the Bad Apple and some other projects (like the PX9 compression demo not being able to draw the whole screen picture wholly during one frame).
So I went and did some tests!
I made three programs. All of them just fill the screen with a solid color each frame, but in different ways.
The first one does it pixel-by-pixel with PSET:
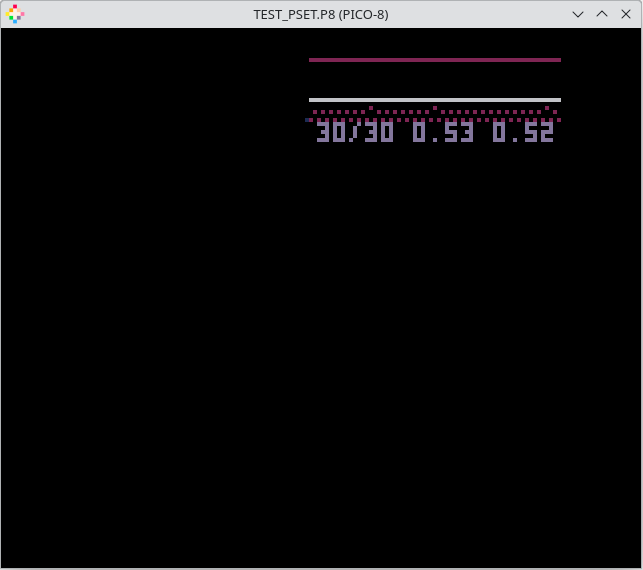
function _update() for y = 0, 127 do for x = 0, 127 do pset(x, y, 0) end end end |
This simple loop ends up taking a whopping 53% CPU:
The second one used LINE, with 128 horizontal lines. I kept the X loop to even out the odds (and yes, I've tested, the interpreter doesn't just optimize it out):
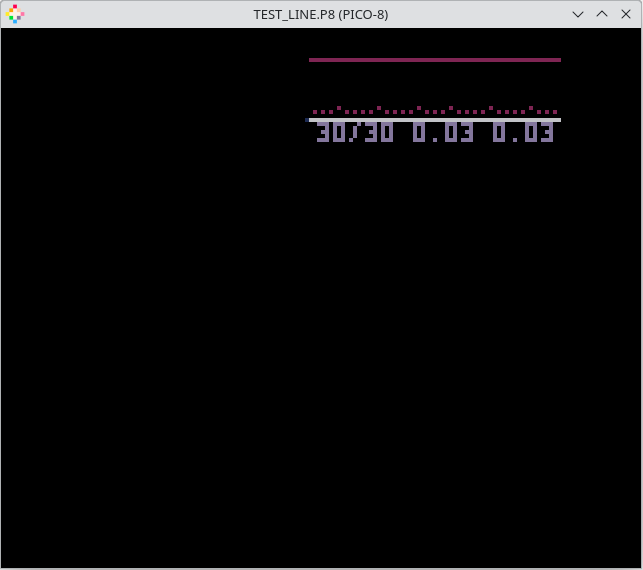
function _update() for y = 0, 127 do for x = 0, 12 do end line(0, y, 127, y, 0) end end |
This improves the CPU metric by a lot. Only 3% is used now:
The final one just does one full-screen RECTFILL. Again, the loops are preserved:
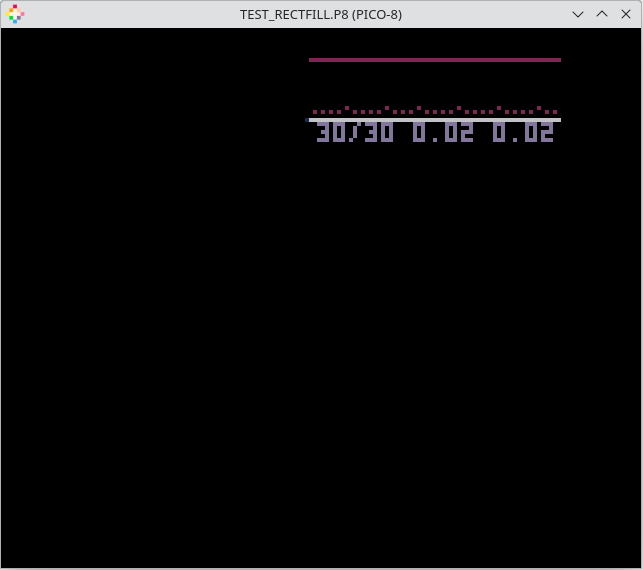
function _update() for y = 0, 127 do for x = 0, 12 do end end rectfill(0, 0, 127, 127, 0) end |
This reports only 2% CPU usage:
I have two hypotheses on what happens. Either, as I said before, the work built-ins like PSET or RECTFILL do does not count towards the CPU limit; or the overhead of function calls is just way too large.
@RealShadowCaster I also tested POKEing the screen memory directly. Running a similar screen-fill test with POKE, POKE2 and POKE4 gave me 24%, 12% and 6% CPU usage respectively:
--POKE test function _update() for i = 0x6000, 0x7fff do poke(i, 0) end end --POKE2 test function _update() for i = 0x6000, 0x7fff, 2 do poke2(i, 0) end end --POKE4 test function _update() for i = 0x6000, 0x7fff, 4 do poke4(i, 0) end end |
@RealShadowCaster looks like function call overhead might be the main culprit here. I changed my PSET test to call a dummy function that does nothing, and it still uses 65% CPU. And when I change it to do a whole-screen RECTFILL instead of each PSET, I get over 100%.
So yeah, I was wrong initially, and CPU time is still being spent inside built-ins. It's just that calling a function introduces a huge overhead, so any rendering code (that doesn't just use MAP() and a couple of SPR()s) needs to aim at reducing the number of function calls.
Either way, my compression method still leaves me a lot of CPU time. Even the original 128x128 15FPS loop only takes up 42% CPU at its peak, and I don't currently do any work at all during frames that I skip.
Too bad, no magic Rectfill I guess.
A simple (but CPU hungry) 64x64 big pixels upscaler :a white mini pixel turns light grey if the three adjacent big pixels are black, and a black mini pixel turns dark grey if the three adjacent big pixels are white.
> I can see why gzip doesn't perform well on a small bit stream when it's elemental input data block is the byte. Maybe give it a raw 1 character per quad input to see if it does better ?
I've tested gzip with one byte per tree node on the 64x64 2.14 FPS data. Gzip turns it into 51978 bytes; my current encoding does better - 44858 bytes. If I do my encoding, and then gzip it, I get 40212 bytes - which is an improvement, but still not worth implementing DEFLATE in Lua :)
If I ever come up with a more compressible qtree representation, though, I will test gzip again.
If I understood your code correctly,
you have 0 and 1 for black and white if at maximal resolution.
otherwise
0 for monochrome square, same color as last of the stream
10 for monochrome square, opposite color as last of the stream
11 for black and white square.
I'm wondering, if instead of referring to the last color of the stream we referred to the color of the pixel to the left of current position, wouldn't we hit the 1bit encoding of big squares more often ?
Another way to reduce the pixel distance between the encoded square and the referenced color to hit the 1bit encoding more frequently would be to keep the encoding but changing transverse order of the image to follow a hilbert curve (like my avatar) rather than the current recursive reading order.
One more idea I want to test is to store the qtree breadth-first instead of depth-first. The logic being that upper tree structure is probably similar between (most) neighboring frames, so if we store that first, we might reuse it between frames. Like, store a byte before each frame that says how many bits to reuse from the start of the previous frame.
I've managed to add the music! And, more importantly, to sync the frames to music. Had to speed it up though.

I'll probably do no huge changes at this point. Will maybe work on the music a bit more, but then I'm done. But it was definitely fun!
@RealShadowCaster, thank you for your help!
@iliazeus : I'm doing tests on pico-8 strings ATM, and it turns out they can be much bigger than I expected.
After 32K length you have to use negative indexes to address the characters, and after 64K you can't address the end of the string directly, but the data is still recoverable with split, if the string is formatted in chunks separated by a delimiter.
Since stat(4) (clipboard) is a string, we may or may not be able to retrieve a lot of extra data this way. There are a lot of security related constraints on the clipboard, but reading it if it has been written by pico-8 is supposed to be allowed... but maybe not if the writing came from another cart ?
Would you be interested in making a "high"-res 128 x 128 version of bad apple if I can make this trick work ? How much data would the final cart need ?
@RealShadowCaster the compressed data itself for the full-res 15 FPS version is about 550K.
I can try to make this work, sure. All the actual rendering code needs is a next_bit() function, so it should be relatively simple to integrate.
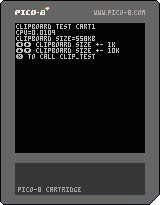
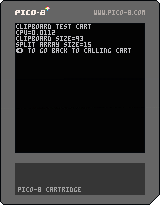
@iliazeus IT WORKS !!! We can use the stat(4) clipboard to send 500Kb of data between two carts. Haven't tested a chain of carts with progressively growing clipboard.
1MB creates an out of memory on the receiver side, don't know the exact limit.
Beware that when it happens, you lose the ability to go back to the caller cart... So everything you may have changed in the caller code will be LOST. Save your caller app after each modification before running.
Sender Cart :
Receiver cart :
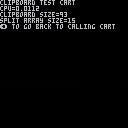
What is tricky is that the string must be separated by a delimiter, and each chuck between delimiters must be 32K or less.
In the cart example, I'm using chunks of 1024 (just 1024 stars) separated by commas.
In your case, I thing every 256 possible values are used, so some escape encoding will be needed to make room for a delimiter.
Or maybe just use any rare character as delimiter, get an array of strings of different sizes, and consider a change of array cell as the delimiter character in the data stream.
@RealShadowCaster I did my own tests, and I can't seem to make it work when running locally. stat(4) always returns an empty string for me.
Does it need to run in the browser, or even on the BBS specifically?
When I put my tests on the BBS, it does not seem to work either; also, it gives a "press Ctrl+C to complete copy" popup. But your carts work fine on the BBS! So I must've been doing something wrong.
Funnily enough, your carts do not seem to change my actual clipboard's contents (at least when I run them here, on the BBS, in Firefox on Linux).
That is, if I set the size to 1K, switch to receiver cart (it reports 1K, as it should), and then try to paste into a text editor, I don't get a thousand stars, but instead get whatever was in my clipboard previously.
The system clipboard and the stat(4) string are two different things.
Only the copy/paste system actions move data between the two.
When I write in the stat(4) string with printh or read it with stat(4), the system clipboard is not touched unless you use the keyboard shortcut.
On BBS, we are lucky the pico8 instance is recycled and stat(4) is not cleared
I think I found the reason my test didn't work!
The clipboard does not handle strings with null bytes in them (chr(0)). And my data was just raw binary, and had nulls in it.
Here's the test confirming that:

I'll try to add some form of escaping, and then give it another go.
Looks like the only unsafe characters are CHR(0) (\0, null) and CHR(13) (\r, carriage return):

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
\0 I’m not too surprised as it’s the C ascii string terminator, \n would have been surprising, but \r is really unexpected. Any idea why ?
The most obvious guess is that something along the way tries to convert \r\n line endings to just \n, and does that by simply removing every \r. But I have no idea why it even cares about line endings in the first place.
Hmm, now I'm hitting 429 Too Many Requests when trying to run it off the BBS.
It has 39 carts total, and hits the limit at about cart 10, I think?
I got to see it without problem on my mac mini (looked awsome for pico-8) , but had to reload 6 times to view it (same wi-fi network) on my Iphone after that. The load would stop further and further into the chain, so some cashing was occurring somewhere.
1st simple thing to add at the end is a replay button, so you don't hit the server 39 extra times if you want to rewatch it (plus the white background of the last frame was in the way). Even if no cart data is sent to the client based on the cart timestamps negociations, it still counts towards the server's requests number.
Not sure what to do there. We'd need more info about the server's setting to not ask too much too fast, but the built-in pseudo-load timer should have taken care of server load, so maybe everything is fine, and you just hit an overall limit while testing ?
Probably wishful thinking, I got the failed loads on the first try on my 2nd device after it viewing it once on my first...
Some progress bar and a "press O to retry cart N" when load fails might be good idea... or maybe it would help the server getting bad apple indigestion...
@zep, did we break any guidelines with this BBS 39 carts pre-load video ?
Edit : @iliazeus did you put the thread offline ?
Here's a recording of me running it locally.
(properly cropped this time)
@RealShadowCaster yes, I did put it offline - the cart did not work reliably, after all.
Honestly, I think I could've gotten away with just doing while (true) load(...). But I'm just not feeling like reuploading all 39 carts at the moment :)
[Please log in to post a comment]